Concurrency and Parallelism in Rust: The Basics
Concurrency and parallelism are often confused, but they solve different problems. In this article, we will demistify both, explain how they work at hardware level and show you how Rust’s tooling such as tokio and rayon makes it practical and safe.
Concurrency vs Parallelism
Concurrency is working at multiple task at the same time. Consider a chef in a restaurant. He managed to do all the work like cooking, chopping vegetables, then checking the oven. Only one action happens at a time.
Parallelism is doing multiple thing at the exact same time. There are multiple chef handling multiple tasks at the same moment. It’s an actual simultaneous work. We need multiple cores or CPU to do true parallelism.
Core vs Thread
We need to understand how concurrency works in core and threads. Modern CPU has two threads per core. Back with the example of a kitchen, consider a chef is working on two pads at once. A chef is a representation of a core, and a pad is executed in a thread. In pad 1, the chef has to boil water for 4 minutes. While waiting for the water to boil, the chef is chopping vegetables for pad 2.
When the water starts boiling, the CPU hardware notices that Thread 1 is stalled (waiting). The chef leaves and start working to chop vegetables, which the task will be executed in thread 2.
The real-world example of “boiling water” is I/O operation such as network calls or reading from storage/database. I/O operation is a delay where the CPU has to wait from outside its chip.
On the other side, chopping vegetables is an example for CPU is doing raw, heavy mathematical calculations and zero-waiting around. The data it needs (vegetable) is already sitting xbeside it in L1/L2 caches.
Rust Concurrency
Handling concurrency while ensuring memory safety is one of Rust major advantage. Historically, problems such as data race and deadlocks are very common when implementing concurrency. By leveraging ownership and type checking, many concurrency errors are prevented in compile-time rather than runtime errors.
To achieve concurrency in Rust, we can utilize the most popular asynchronous runtime, tokio. Consider this example:
use tokio::time::{Duration, sleep};
async fn run_task(task_name: &str) {
println!("task {} start", task_name);
sleep(Duration::from_millis(100)).await;
println!("task {} end", task_name);
}
#[tokio::main]
async fn main() {
tokio::join!(run_task("A"), run_task("B"), run_task("C"));
}
In above code, we have an async function run_task which executes sleep function inside. See below output:
task "A" start
task "B" start
task "C" start
task "B" end
task "C" end
task "A" end
Notice that the task B starts when task A is sleeping. Task C starts when task B is sleeping. During that 100ms sleep time, tokio reschedules the tasks and pick whatever the CPU scheduling picks. The result could be different between executions, depends on how the operating system schedules this thread.
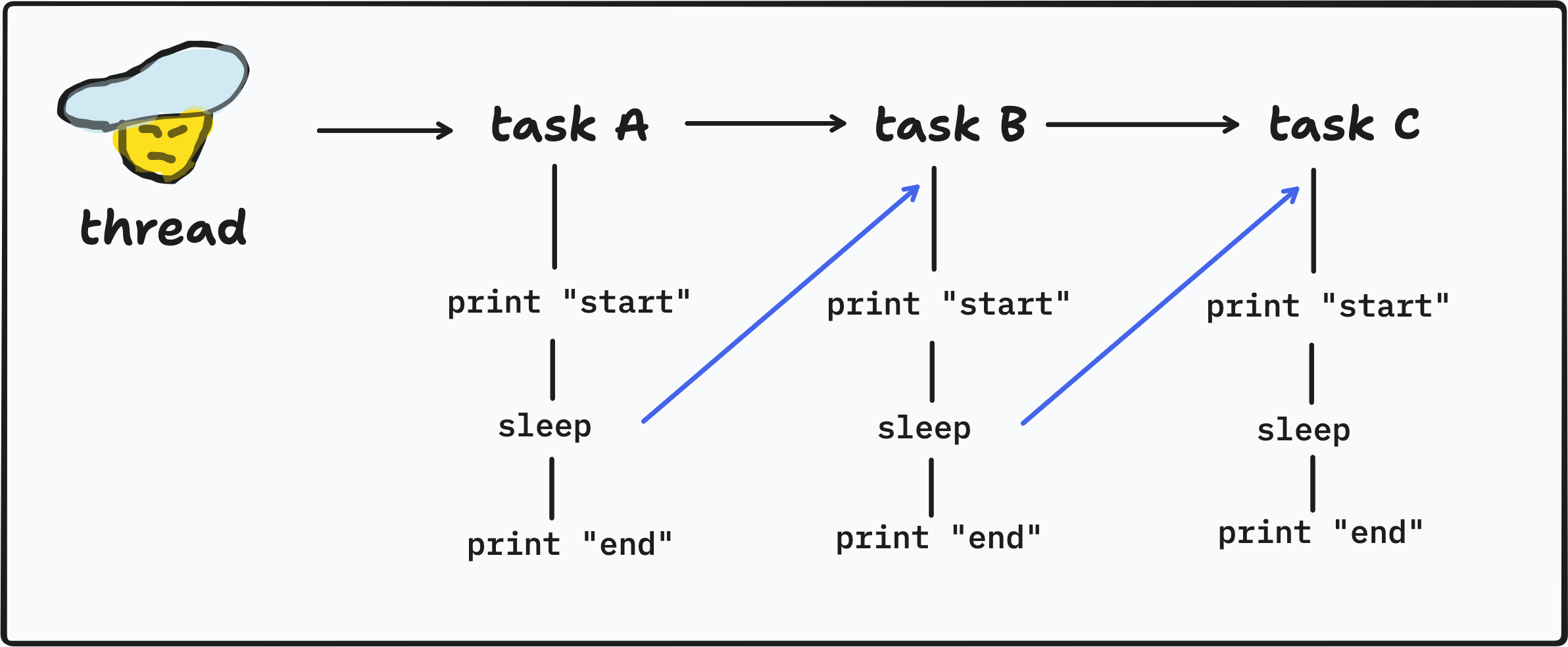
Look at the blue arrow above. It yields when there is an .await, meaning the thread is allowed to do another task while waiting.
For those who are familiar with JavaScript, it is equivalent to Promise.all(run_task("A"), run_task("B"), run_task("C")).
Tokio also provides spawn function that immediately spawn a thread to run the work inside an async block. Let’s rewrite the example above to use tokio::spawn!
#[tokio::main]
async fn main() {
let (result1, result2, result3) = tokio::join!(
tokio::spawn(run_task("A")),
tokio::spawn(run_task("B")),
tokio::spawn(run_task("C"))
);
}
tokio::join! handle multiple async tasks in a single thread. Like a multitasking chef from earlier examples. When we use tokio::spawn for each task, we are summoning new chef to handle the task. In this example, three threads are spawned.
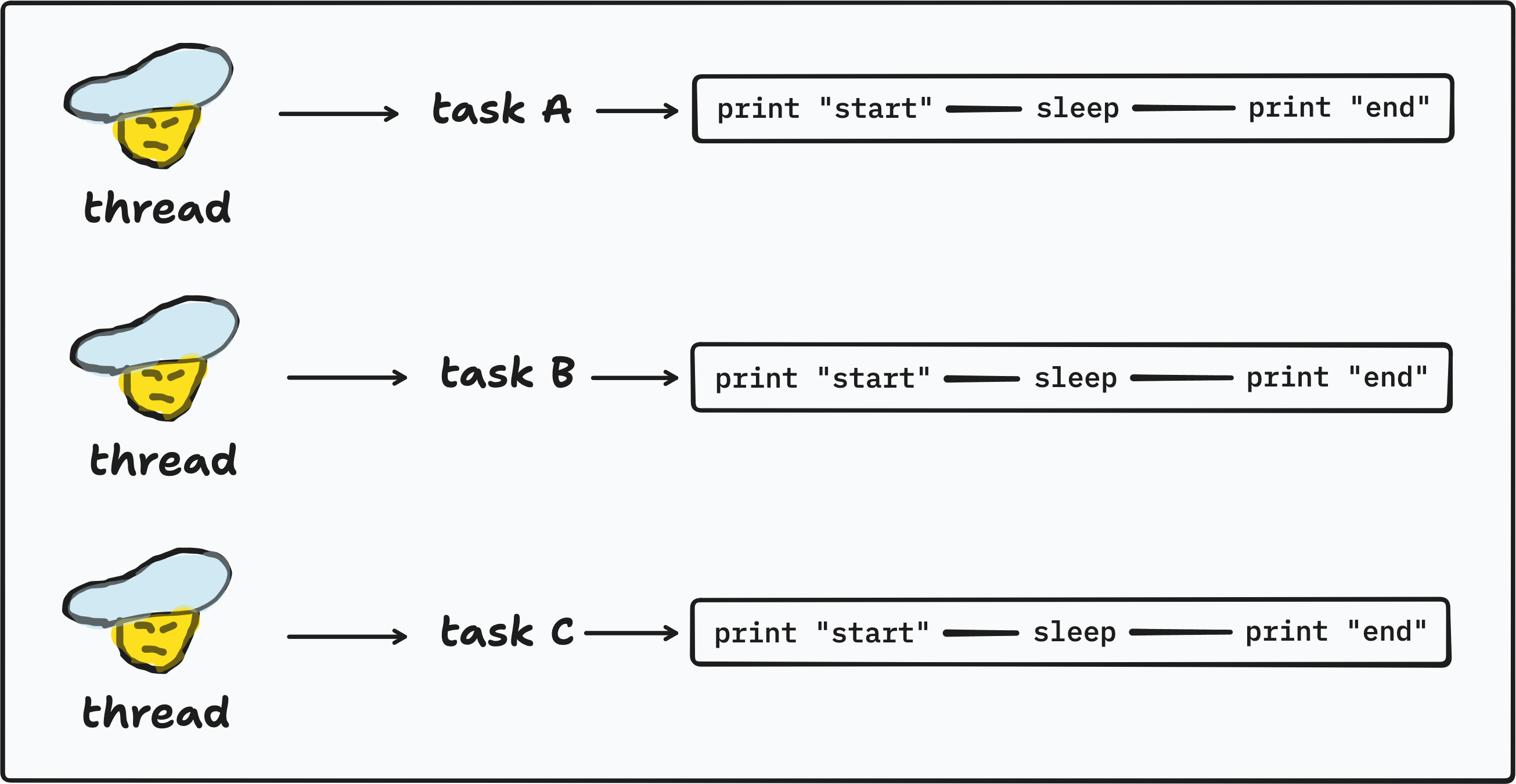
If there is no .await point in the task, the thread will be blocked to focus on that task. The chef has to focus on that single task, he can’t switch to another task while working on it. Check out this example:
tokio::spawn(async {
for i in 0..1_000_000_000 {
heavy_math(i);
}
});
We spawn a thread to do a long and heavy task that will block the thread. This is bad because the thread can’t yield to do another task while working on that long task.

Better way to put this is to use tokio::spawn_blocking which spawn a separate thread to work do CPU-heavy or blocking synchronous task so it won’t block the main async executor.
fn run_heavy_task() {
let mut result = 0;
for i in 0..1_000_000 {
result += i / 1000;
}
println!("computation result: {result}")
}
#[tokio::main]
async fn main() {
tokio::join!(
tokio::task::spawn_blocking(run_heavy_task),
tokio::spawn(run_task("A")),
tokio::spawn(run_task("B")),
tokio::spawn(run_task("C")),
);
}
Now we have a “heavy” computation task which is a sync and blocking process. In this example, we spawn two thread: an async thread and a blocking thread. Can you guess the output?
task A start
task B start
task C start
computation result: 499500000
task C end
task B end
task A end
The async worker thread assigns threads to run run_task, it works perfectly like we did above. Additionally, we launch a real OS blocking thread to start grinding on heavy work. The blocking thread immediately runs at start without checking whether the async thread are busy. It does not ask permission.
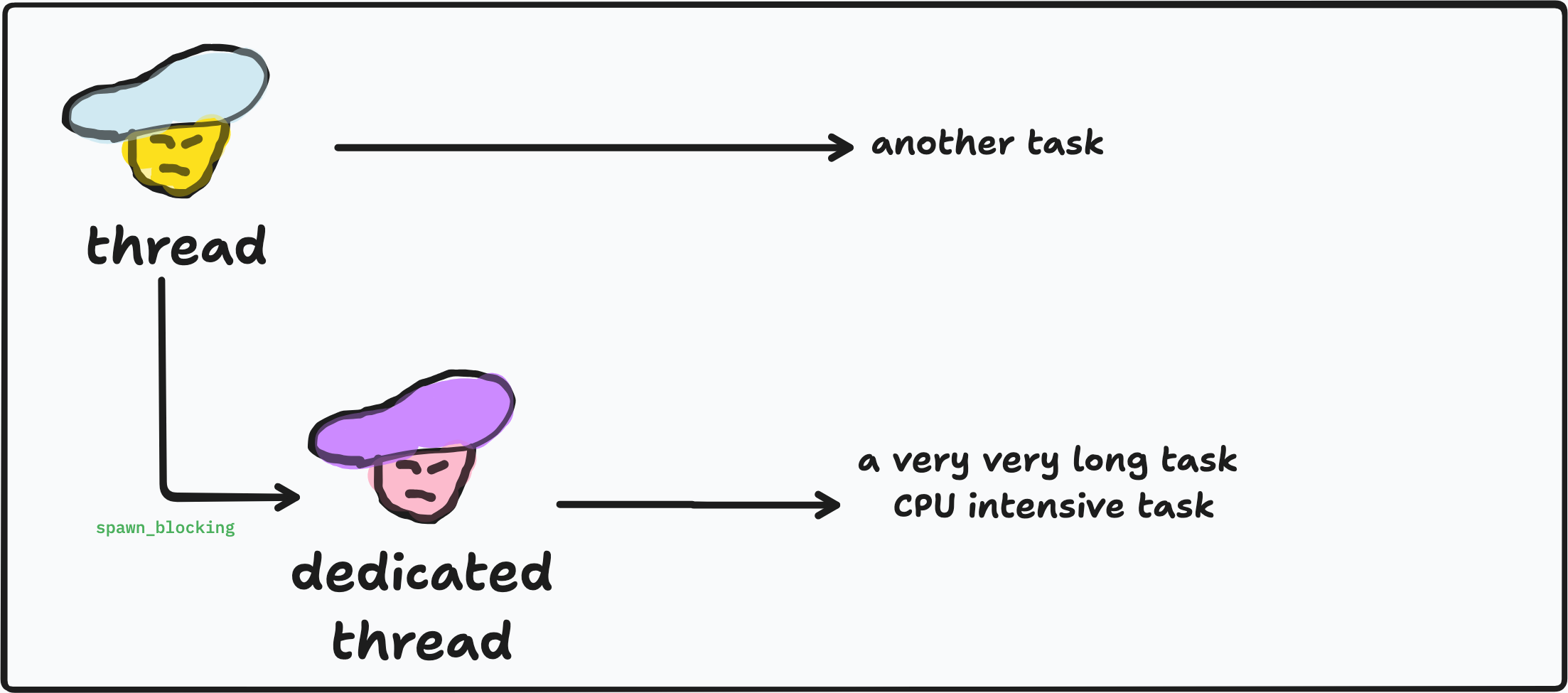
By spawning blocking thread, that CPU-heavy task is no longer blocking the thread as it’s moved to a separate OS thread, so both can run separately. It’s like the chef spawns another chef to work on that specific task.
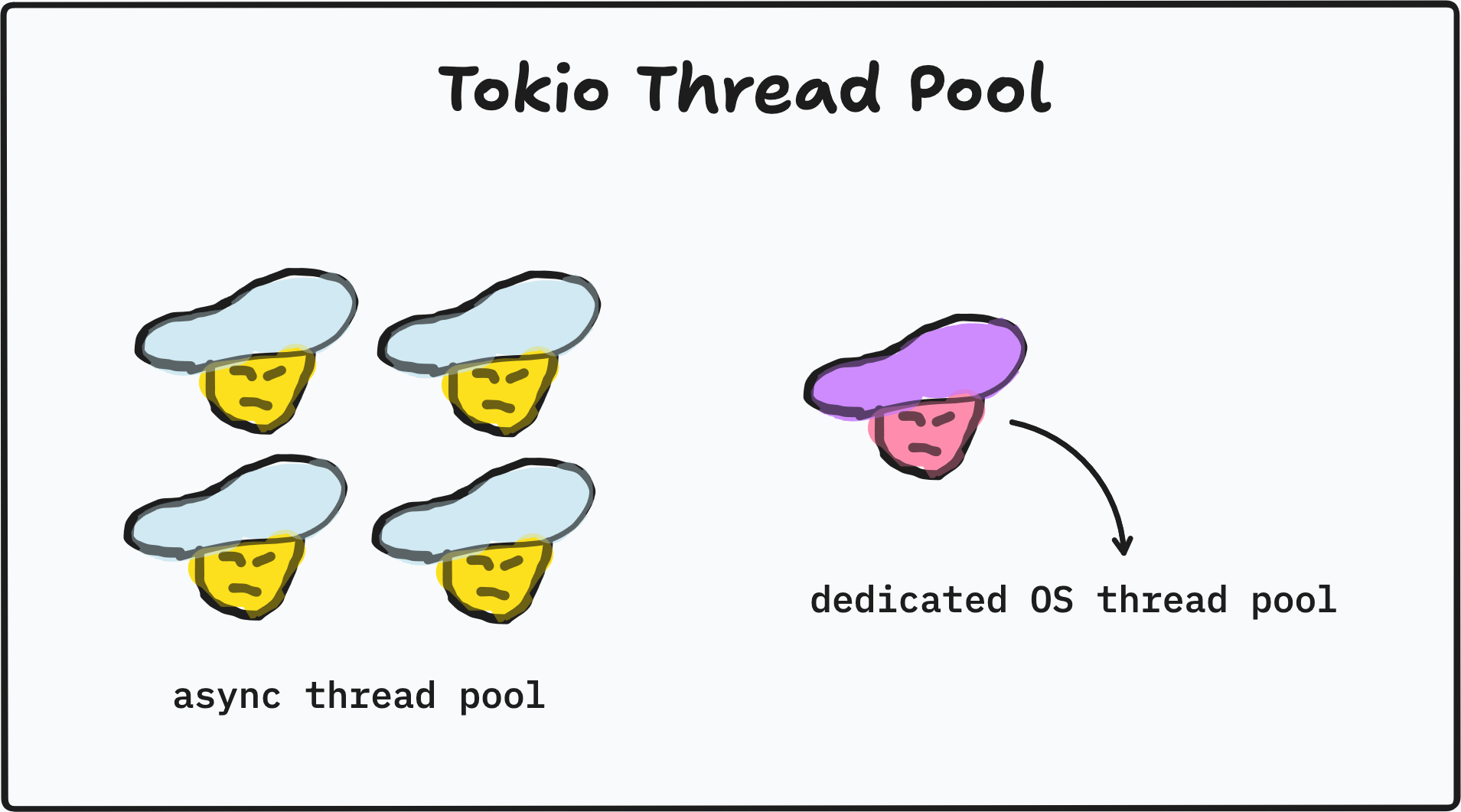
Tokio manages two separate pools of threads: async worker pool and blocking thread pool. For the async worker pool, tokio by default spawns a number of threads defaulting by one per CPU core. We call it cooperative multitasking, where thousands of tasks can be multiplexed across just few workers. The threads are maintained by tokio’s scheduler, an application-level scheduler that built on top of fixed allocation of OS threads.
On the other hand, spawn_blocking creates a dedicated OS thread managed by the OS scheduler (not tokio). Unlike the fixed async worker pool, this blocking thread pool grows on demand. Tokio spawns a new OS thread for each spawn_blocking call, up to a configurable max (default is 512). This is important because OS threads are expensive: each one costs memory for its stack (typically 2–8 MB) and CPU time for context switching. So you should use spawn_blocking to isolate blocking work from the async runtime, not to parallelize CPU work across cores. For true parallelism, we need a different tool: Rayon.
Parallelizing the process
Concurrency is not a true parallelism. It’s just a thread working on multiple tasks at the same time. To achieve true parallelism—multiple tasks are working at the exact same time—we can use rayon crate. Rayon converts sequential computations into parallel.
Rayon is always a good pick when parallelizing your processes. But there is an exception: it will create overhead that will outweigh the benefits of parallelizing your code if your unit of parallelism too small.
Rayon provides a high-level parallel constructs, the simplest way to use Rayon which is parallel iterators. Instead of using .iter() like you’d normally use, you can utilize .par_iter() instead.
use rayon::prelude::*;
#[tokio::main]
async fn main() {
let tasks = [1, 2, 3, 4, 5];
let result = tasks.par_iter().map(|task| run_heavy_task(task)).collect();
}
By default, rayon creates one thread per logical CPU core in your system. If you have 4 cores 4 threads, rayon by default will span 4 threads. In this example, suppose we have 5 array item running in 4 threads. .par_iter() delegates each item to a worker thread and collect them all in order when a worker finished.
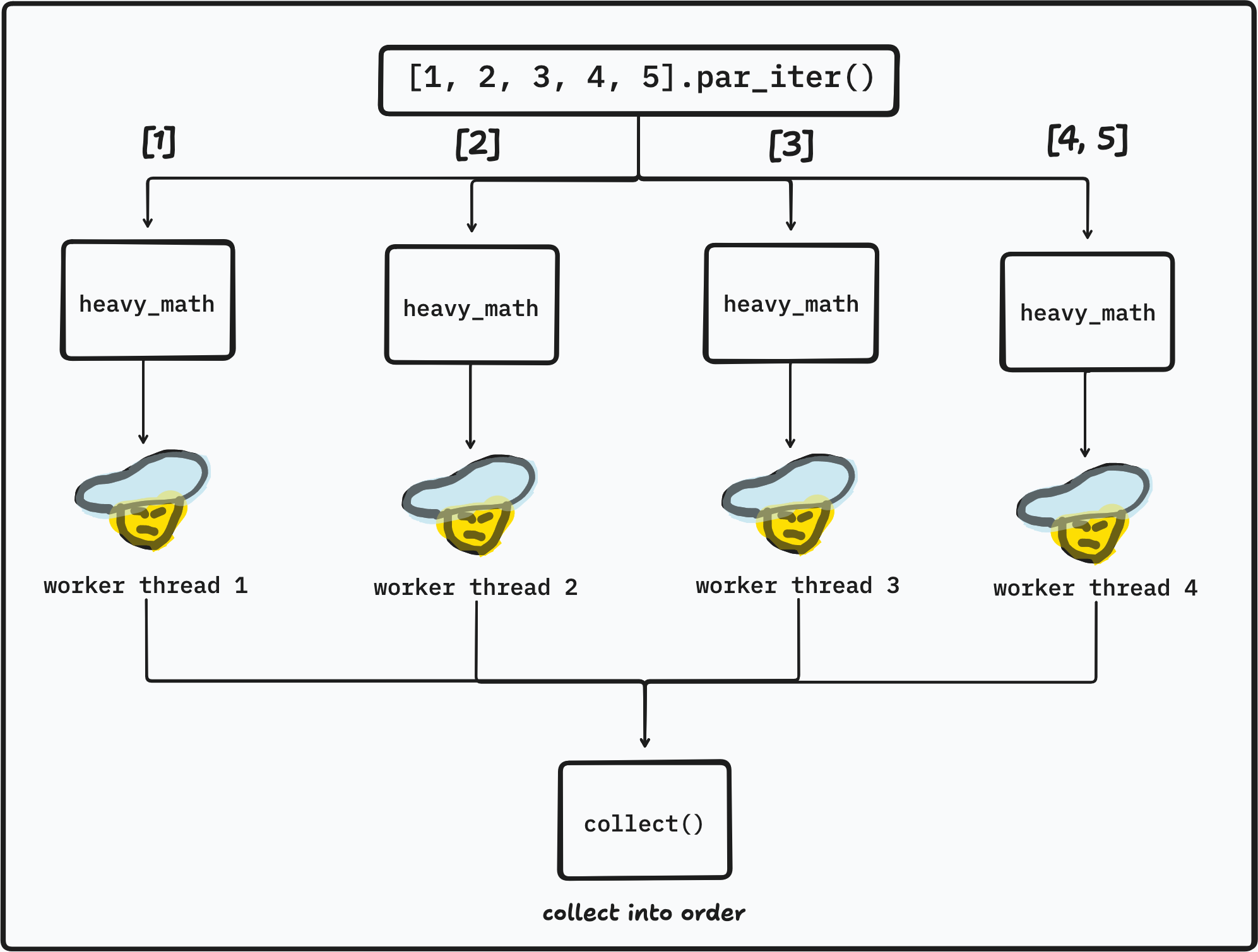
In the image above, each workers are assigned a heavy task to work on. But notice that the Worker 4 is assigned two tasks: computing the number 4 and 5. When the Worker 1 finished its task early, it will steal Worker 4’s task to compute 5. This is called work-stealing, a scheduling algorithm that balances workloads among multiple workers or threads.
Real-world use case
Take a look at burn codebase, a deep learning framework for building and running AI models in Rust, to see how it uses Rayon’s .into_par_iter when the rayon feature is enabled. It runs heavy computations with many nested iterations inside a loop.
We can also use rayon or Tokio’s spawn_blocking to process or transform image pixel data—a CPU-intensive workload. In my optimizing image pipelines article, we deal with both CPU-heavy computation and I/O-bound inference. A good way to improve performance is to wrap the computation in spawn_blocking so it doesn’t block the async runtime.
Wrapping it up
Whether to choose parallelism or concurrency, it depends on your use cases. Don’t use Rayon for everything and assume everything will be faster instantly. Don’t blindly use spawn or spawn_blocking for everything. Use the right tool for the job.
At the end of the day, Rust gives you the power to choose how you want to use your resources. Understanding the difference between concurrency and parallelism — and picking the right runtime for the job — is what separates a working program from a fast one.